
What Are MTTD and MTTR?
MTTD (Mean Time To Detect) and MTTR (Mean Time To Resolve) are two important metrics used to measure the performance of an organization’s incident management process.
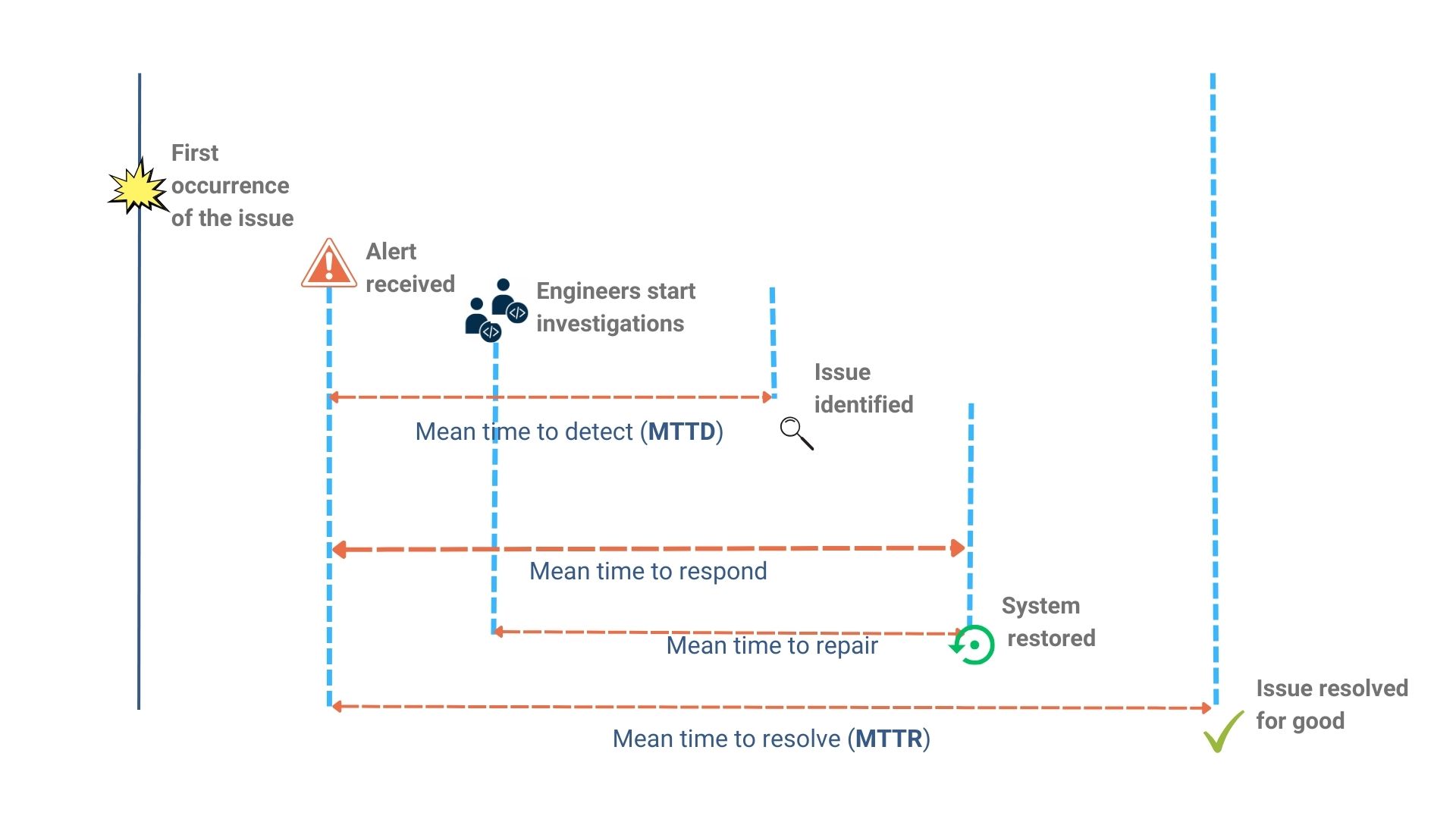
MTTD is the mean time an organization takes to detect the existence of issues from their first occurrences. If an organization runs into 12 system failures in a week, the MTTD is calculated as the average time taken to detect the issue across those 12 failures.
MTTR is the mean time an organization takes to permanently fix a failure in the system since the problem was reported. This includes the time taken to detect, diagnose, repair, and permanently fix the failure so that it doesn’t recur.
Both MTTR and MTTD can be impacted by a number of factors, including the complexity of the issue, the skills of the incident response team, and the availability of resources in terms of both infrastructure and manpower.
Why Do They Matter?
Before we dive straight into determining MTTD and MTTR, let’s first take a look at why they matter to an organization. First and foremost, the downtime of an SaaS application can impact multiple key factors such as user experience, customer trust, an organization’s credibility, reliability, and cost.
According to a recent survey by ITIC, the average cost of just one hour of downtime for a large enterprise can amount to over $300,000. This includes the direct costs associated with lost productivity and revenue as well as indirect costs such as damage to reputation and brand value.
According to Gartner, the average cost of IT downtime is $5,600 per minute. Based on the type of business and operations the average cost of downtime can vary between $140,000 per hour and $540,000 per hour at the higher end.
To minimize the cost of downtime, enterprises need to invest in reliable hardware and software. Moreover, they should have a good plan in place for how to recover from any disruptions. This is where MTTD and MTTR play an important role. The ability to detect and permanently resolve issues early is a KPI that all enterprise software organizations should keenly monitor.
How To Measure MTTD and MTTR
Formula for measuring MTTD:
sum(time when the issue was detected - time when the issue occurred) / total number of issues during the interval (week, month, quarter)Formula for measuring MTTR:
sum(time the issue was fixed permanently - time when the issue occurred) / total number of issues during the interval (week, month, quarter)Organizations can also use a number of tools and techniques to measure MTTR and MTTD, such as logging system data, tracking incident tickets, and conducting post-incident reviews. Using robust observability stacks also allows teams to gain more visibility into the environment and context within which the system is running.
For example, as part of an investigation, looking into the logs, metrics, and traces will accurately provide the time at which the issue originally occurred. If there is a ticketing, on-call alerting system in place, it can provide the first time the issue was reported. Additionally, adopting a black box testing approach to constantly monitor user-facing systems can also help to accurately measure your MTTD and MTTR.
How To Improve MTTR and MTTD
As mentioned before, organizations use these metrics to track the efficiency of their incident management processes and compare them to industry benchmarks.
If you’re looking to improve your organization’s MTTR and MTTD, you should start by looking at the DORA metrics. The DORA, or DevOps Research and Assessment, metrics are a set of metrics that measure an organization’s performance in four key areas:
- Delivery: How quickly can we get features into production?
- Innovation: How quickly can we experiment and learn?
- Optimization: How well are we able to keep our systems running?
- Security: How well are we protecting our systems and data?
Organizations that perform well in all four areas are considered “elite performers“. In fact, the DORA metrics are often used to assess an organization’s progress on their journey to “elite” status.
So, how can you improve your organization’s MTTR and MTTD? Here are a few ideas:
- Make sure you have a clear understanding of your organization’s DORA metric scores. This will help you identify areas of improvement.
- Focus on improving your delivery process. The faster you can get features into production, the faster you can identify and fix issues.
- Make sure you foster a culture of experimentation and learning. Encourage your team to experiment and to learn from its mistakes.
- Improve your monitoring and logging protocols. This will help you identify issues faster and minimize the impact of outages.
If you found this article helpful, stay tuned for the next one in this series: Tools You Can Use To Help Improve Your MTTD and MTTR.
OpsVerse ObserveNow is a managed, battle-tested, scalable observability platform built on top of open source software and open standards. ObserveNow can be deployed as a cloud service or as a private SaaS installation within your own cloud (AWS/GCS/Azure). If you’d like to explore OpsVerse ObserveNow, click here to start a free trial today!









